on
Attention is all you need
Have you ever tried reading Attention is All You Need paper- the groundbreaking Transformer paper - and felt overwhelmed by its technical density? You’re not alone. While this paper revolutionized natural language processing and laid the foundation for models like BERT, GPT, and modern LLMs, its academic style and mathematical detail can make it challenging for newcomers. This blog post serves as a friendly companion to the paper, breaking down its core concepts using familiar analogies and visual explanations. Think of it as a warm-up before diving into the technical depths of the original paper. We’ll explore the key innovations of the Transformer architecture - particularly its attention mechanism - using analogies from Star Wars and Harry Potter, along with clear visualizations. Whether you’re preparing to read the paper for the first time or looking to better understand concepts you’ve previously encountered, this guide will help build an intuitive understanding of how and why Transformers work.
RNNs (Recurrent Neural Network) and LSTM (Long Short-Term Memory) were the state-of-the-art for sequence tasks like translation, but their sequential nature limits parallelization and efficiency. The paper proposes Transformer architecture, that replaces recurrence with attention mechanisms, enabling parallel processing and achieving superior translation quality with significantly less training time. As illustrated in Figure 1, the key architectural difference between RNNs and Transformers lies in their processing approach. The RNN/LSTM model (left) processes inputs sequentially through a chain of hidden states, where each state depends on the previous one - Input1 must be processed before Input2, and so on. In contrast, the Transformer model (right) handles all inputs simultaneously through its self-attention mechanism, allowing parallel processing of the entire sequence. This parallel architecture enables the Transformer to be more computationally efficient, as it doesn’t need to wait for previous inputs to be processed before handling the next ones. The self-attention mechanism acts as a central hub that directly connects all inputs to all outputs, enabling the model to weigh and process relationships between elementssimultaneously, regardless of their positions.
Figure 1: Transformer Model vs RNN/LSTM Model
Concept of Attention
Before we dive into the Transformer architecture, let’s first understand the concept of attention, with Start Wars and Harry Potter Analogy.
Star Wars Analogy: When lifting the X-wing from the swamp, Luke specifically focuses on the X-wing (high attention weight) while ignoring rocks and trees (low attention weights), even though all objects are within his Force reach.

Luke focuses on lifting the X-wing from the swamp
Harry Potter Analogy: When Harry casts his strongest Patronus, he doesn’t give equal weight to all memories. Instead, he specifically focuses on powerful happy memories (high attention) while automatically filtering out memories of the Dursleys (low attention), even though all memories are technically available to him.

Harry Potter focuses on his memories to cast his strongest Patronus
In both cases, attention works like a selective focus mechanism, automatically weighing what’s important for the current task while still having access to everything.
Attention Mechanism in Transformer Architecture
The Attention mechanism is a fundamental innovation in the Transformer architecture that enables the model to focus on relevant parts of the input when producing output. However, when processing language, a single attention mechanism may be insufficient to capture the complexity of language. Just as humans understand language by simultaneously considering multiple aspects like grammar, context, and tone, the model needs to analyze the input from various perspectives. This is where Multi-Head Attention becomes crucial.
Multi-Head Attention Multi-Head Attention works like a team of experts studying a problem from different angles. Instead of one person analyzing everything, you have eight specialists each focusing on different aspects - like how your brain simultaneously processes grammar, context, and tone in a sentence. One head might focus on grammar, another on context, while others look at word relationships. Their individual findings are then combined to create a complete understanding, making it powerful at catching various patterns and connections in the data.
Focus on grammar] & H2[Head 2
Focus on context] & H3[Head 3
Focus on tense] & H4[Head 4
...] H1 & H2 & H3 & H4 --> C[Combine Results] C --> O[Final Output]
Figure 2: Conceptual view of Multi-Head Attention
Encoder & Decoder
Encoder and Decoder are the two main components of the Transformer architecture. We can think of the encoder as a thorough reader creating a complete understanding, and the decoder as a careful writer using that understanding to generate output one piece at a time. Transformer architecture uses encoder-decoder model to process sequence data.
- The Encoder takes input sequence (like an English sentence) and transforms it into a continuous representation (z) that, in some sense, captures the meaning.
- The Decoder generates the output sequence (like a French translation) one element at time, using both the encoded representation and its own previously generated outputs
Figure 3: Simplified, high level view of Encoder & Decoder
Putting it all together
The image on the right is taken from the paper.
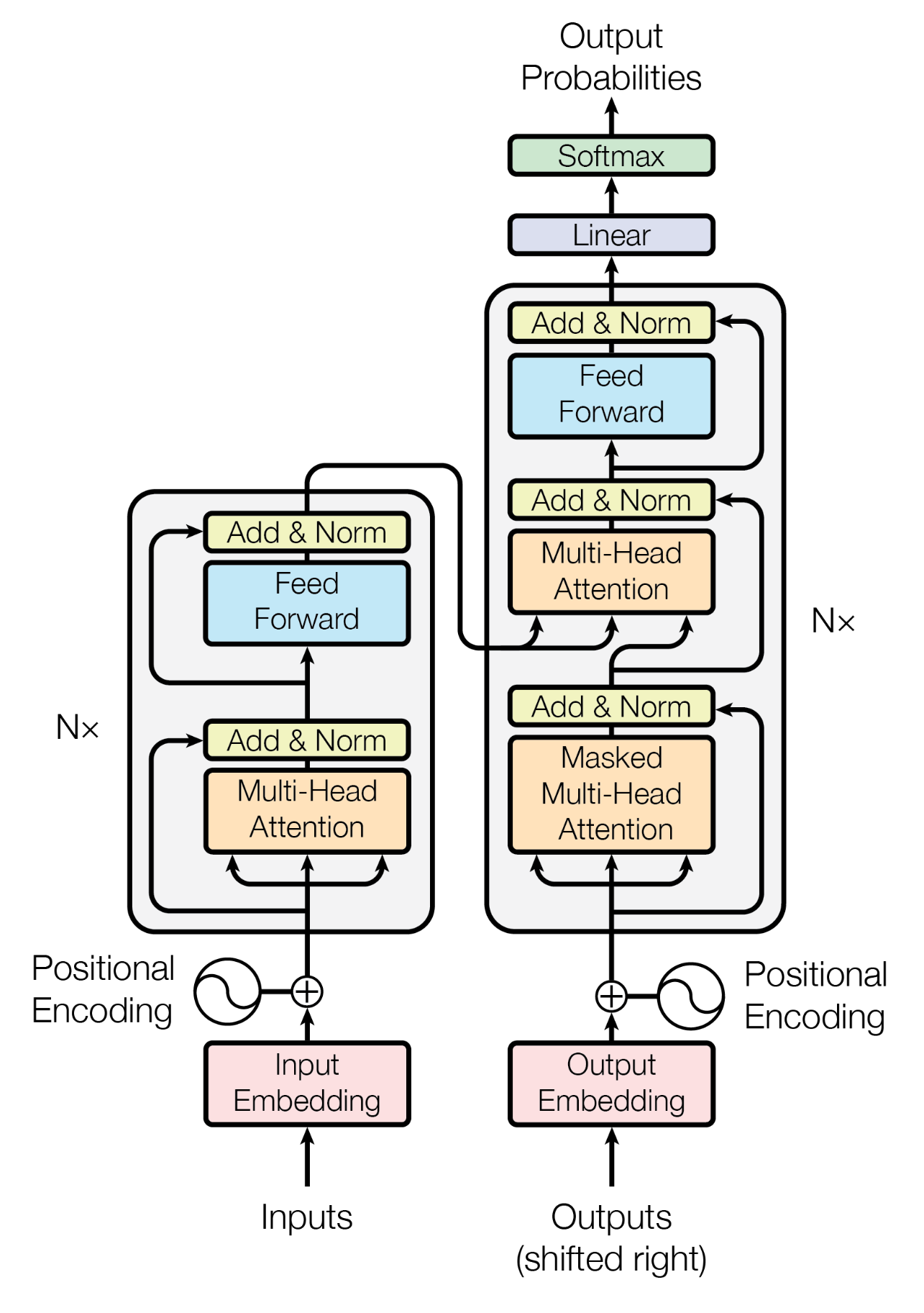
In the Transformer model, at its core, the encoder processes the entire input simultaneously, while the decoder generates output sequentially. The architecture’s key innovation lies in its multi-head attention mechanism, where eight parallel attention processors analyze different aspects of the input concurrently - capturing elements like grammar, context, and word relationships.
The Processing Pipeline: Each input first receives positional encoding - a clever way to timestamp words since the model processes them simultaneously. The data then flows through multiple layers of processing, each containing two main components: attention mechanisms and feed-forward networks. The feed-forward networks consist of two linear transformations with a ReLU activation (a simple function that passes positive numbers unchanged while zeroing out negatives) in between, processing information from the attention layer.
The Transformer employs several techniques to maintain stable and effective training. Residual connections act as shortcuts, adding each layer’s input to its output to prevent signal degradation in deep networks. Layer normalization stabilizes the learning process by standardizing values at each layer, similar to standardizing test scores. Finally, the softmax function converts the model’s raw outputs into probabilities, enabling the model to make decisions about word selection in tasks like translation.
Through this combination of innovative components, the Transformer achieves high-quality sequence transformations more efficiently than its predecessors, setting new standards in natural language processing tasks.
- If you would like to get your hands dirty with the Transformer architecture, here are some resources:
- Illustrated Transformer by Jay Alammar - A visual deep dive into the architecture
- Try implementing a simple Transformer using PyTorch's tutorial or TensorFlow's guide
- Experiment with Hugging Face's Transformers library to understand practical applications
- Andrej Karpathy's minGPT implementation for a minimalistic Transformer
- The Annotated Transformer by Harvard NLP group
- If you are interested in understanding the Transformer architecture in more detail, here are some resources:
- Explore recent Transformer variants like BERT, GPT, and T5
- Read "Language Models are Few-Shot Learners" (GPT-3 paper) to understand scaling effects
- Study "Attention Is All You Need" paper's implementation details and mathematical foundations
- If you are interested in AI and machine learning, here are some resources:
- Stanford CS224N NLP with Deep Learning course materials
- "Natural Language Processing with Transformers" book by Lewis Tunstall et al.